共计 2803 个字符,预计需要花费 8 分钟才能阅读完成。
引子:一个零件架的教训
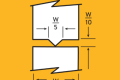
一个工程师设计三层支架,每层高度 20 ± 0.2 mm,总高要求 60 ± 0.5 mm。 他拍了拍脑袋:单层允差 0.4,三层 1.2,不到总公差 1.0 的一半——稳了。 结果做出来,50 套里有 12 套超差。 为什么?因为他用了极值法的思路——但算错了。公差不是简单线性叠加,关键看你怎么积。
一、极值法(WC,Worst Case)
原理
最坏情况:把所有零件都推到公差极限。 总公差 = 各零件公差的算术和
T_wc = T1 + T2 + T3 + ... + Tn
用前面的支架案例:
T_wc = 0.4 + 0.4 + 0.4 = 1.2 mm
设计总要求 60 ± 0.5 mm → 总公差 1.0 mm。 1.2 > 1.0 → 不合格。 设计师需要把单层公差压到 ± 0.167 mm 才能过——代价太大了。
什么时候用
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
优缺点
➕ 绝对安全——只要单个零件合格,装配一定合格 ➖ 公差会被「吃掉」得很快——5 个零件一叠就只剩 1/5
二、RSS 法(Root Sum Square)
原理
假设每个零件的偏差是独立正态的。既然不是线性叠加,那就按平方和开方。
T_rss = sqrt(T1^2 + T2^2 + T3^2 + ... + Tn^2)
还是那个案例:
T_rss = sqrt(0.4^2 + 0.4^2 + 0.4^2) = 0.693 mm
0.693 < 1.0 → 合格。 设计师不用压单层公差了,20 ± 0.2 的零件可以直接用。
数学直觉:为什么 RSS 比 WC 小?
形象化理解:两个正态变量叠加——最大偏差同时发生的概率很低。
-
WC 假设的是 100% 同时发生 -
RSS 假设的是独立随机叠加
三个 ±0.2 的零件,同时都偏到上端或下端(+0.2 同时发生)的概率是 0.3% × 0.3% × 0.3% ≈ 27 亿分之一——现实中基本不会发生。
前提条件——非常重要
RSS 有两个致命前提:
- 各零件的偏差服从正态分布
(看完上篇你知道这不一定成立) - 各零件的偏差相互独立
(使用同一台机床加工的零件可能不独立!)
不满足前提,RSS 的结果就是错的。
修正版 RSS
工程上常用的修正: 考虑 CPK 和均值偏移,引入一个系数:
T_rss_adj = C_f * sqrt( T1^2 + T2^2 + ... + Tn^2 )
C_f 取值:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
三、Monte Carlo 模拟
原理
不假设任何分布。你直接告诉程序:
-
零件 A:正态分布,均值 20,标准差 0.067(对应 ±0.2 @ CPK 1.0) -
零件 B:偏态分布,左偏,用实测数据拟合 -
零件 C:均匀分布,20 ± 0.2
然后抽一万次,每次随机取一组值,算出装配后的总尺寸。 一万次之后,看总尺寸的直方图——超差比例一目了然。

工具
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
Python 代码示意(30 行搞定)
import numpy as np
n_samples = 10000
# 零件A:正态
A = np.random.normal(20, 0.067, n_samples)
# 零件B:偏态(用 Beta 分布模拟)
B = 20 + 0.2 * (np.random.beta(2, 5, n_samples) * 2 - 1)
# 零件C:均匀
C = np.random.uniform(19.8, 20.2, n_samples)
# 总高度
total = A + B + C
# 超差率
defect_rate = np.mean((total < 59.5) | (total > 60.5))
print(f"缺陷率: {defect_rate:.4f}")
工程经验:一般 N = 5000 ~ 10000 就够稳定了。
Monte Carlo vs RSS
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四、3D 公差分析(3DCS / CETOL)
解决了什么问题
上面三种方法都是一维尺寸链——只能算线性叠加。 但现实中公差是被三维传递的:
-
孔轴配合:间隙 0.05 → 角度偏摆 0.1° -
平面度 + 位置度:二维叠加 -
平行度 + 垂直度:方向性公差的耦合
这些一维方法算不了。
怎么做
在 CAD 模型上直接标注公差:
-
选基准(Datum) -
标公差(GD&T 符号) -
定装配顺序(先装哪个零件,对准哪些面) -
运行 Monte Carlo(1000 ~ 10000 次) -
看结果:关键间隙的分布 + 敏感度排名
主流软件
|
|
|
|
|---|---|---|
| 3DCS |
|
|
| CETOL 6σ |
|
|
| VisVSA |
|
|
什么时候需要上 3D 分析?
-
装配涉及角度、方向公差(垂直度、平行度、位置度) -
有柔性件(线束、密封条)参与 -
批量大(年产量 > 10 万),省 0.1 mm 公差 = 省几十万
五、决策树:到底用哪种?
零件数量 ≤ 3 或者安全件?
├── 是 → 极值法(WC),简单安全
└── 否 → 继续
所有零件正态且独立?
├── 是 → RSS 法,快速有效
└── 否 → 继续
有实测分布数据?
├── 是 → Monte Carlo,准确灵活
└── 否 → 继续
有 3D 公差传递(角度/方向)?
├── 是 → 3DCS/CETOL
└── 否 → Monte Carlo
打样阶段没数据?
├── 是 → 先用极值法,量产后再切换
└── 否 → 按数据定
六、新手最常犯的 3 个错误
错误 1:不管分布直接用 RSS
“供应商说 CPK > 1.33,我直接套 RSS”
供应商给的 CPK 可能是全检后的截断数据算出来的——CPK 2.0 是假的。 正确做法:要原始工艺波动数据(包含超差件),自己算分布类型。
错误 2:忽略均值偏移
“公差 ±0.2,均值就应该在中间”
实际生产中,刀具的偏移、模具的磨损会让均值偏向一侧。 如果均值偏移了 0.1,RSS 算得再准也是错的。 正确做法:查一下实际均值。如果有显著偏移,用修正 RSS 或 Monte Carlo。
错误 3:零件越多,RSS 越省公差
这是一个直觉陷阱。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
RSS 节约的比例确实随零件数增加而增大——但前提是所有零件真的服从独立正态。 如果一个注塑件是偏态的,另一个冲压件是肥尾的,那 RSS 的节约就是纸上谈兵。
七、总结
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话记住:初期没数据用极值法,量产过 CPK 后用 RSS,非正态分布上 Monte Carlo,涉及方向位置做 3D 分析。


 yangzhan_83
质量门板块有点乱,另外缺少快速反应板块。
yangzhan_83
质量门板块有点乱,另外缺少快速反应板块。
 hello world
hello world
hello world
hello world
hello world
hello world
 infinite cui
需求VDA6.3 表格,谢谢
infinite cui
需求VDA6.3 表格,谢谢
 john
如何获得这个PPT文件
john
如何获得这个PPT文件